
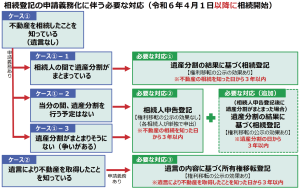
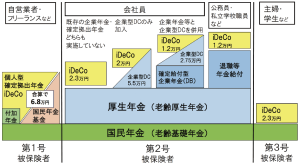
第70回 業務に生成AIを活用する方法②
情報セキュリティ連載
試される人工知能「チャットGPT」の実力
前回より、生成AIの業務利用についてのお話をさせていただいております。
今回は、マルチモーダル生成AIという機能の現状と、より詳しいプロンプト指示についてお話いたします。
1 マルチモーダル生成AIとは
マルチモーダル生成AIとは、従来の生成AIが指示を受ける形式が文字情報をベースにしているのに対し、マルチモーダル生成AIは、指示の受ける形式が画像、動画、音声等文字以外のデータもできる生成AIです。
マルチモーダル生成AIは、画像や動画音声等文字データ以外のデータを入力することで、より広範囲の作業を可能にしています。
このマルチモーダル生成AIについては、Googleの生成AIがいちはやく展開、ChatGPTもこれに追従する形でサービスを展開している状況です。
2 マルチモーダル生成AIの構造
では、マルチモーダル生成AIは文字データ以外のデータをどのようにして指示をうけているのかを見ていきましょう。
構造はさほど難しくなく、画像や動画、音声から旧来のAIがまず文字データへ変換します。
旧来のAIとは画像認識や音声認識専用のAIを示します。
これら旧来のAIが文字起こしを行い、生成AIへデータを流します。生成AIがこの文字情報を元に、指示された命令文から答えを生成する構成です。
旧来のAIは文字を認識したまま文字を起こします。現状この文字データを元に、生成AIは指示に従います。従って、認識された文字情報が人の意図しない形で文字の改行された状態で生成AIへ渡され、場合によっては意図しない回答が生成されてしまいます。
3 マルチモーダル生成AIの現状
上記のように、事前処理や否定形データの処理等を自動でやってくれるマルチモーダル生成AIですが、従来の特化したAIからの情報をプロントの文脈から要求に応じる形を取ります。
従来のAIで人の手が必要なデータは、手を加える等をしてあげないと、現状では求める答えにはたどり着かないのが現状だと思います。
4 生成AIにおいて重要となるのはやはりプロンプト
上記のように文章の画像解析は画像認識AIでは人が求めるようなものが100%できないのが現状です。実感としては8割というところです。
やはりデータ起こしなどは、特化した旧来のAIのほうが得意のようです。
実際の業務においては、文字等の抽出は旧来の特化型AIで抽出、人のチェックを通して生成AIへ流すのが、確実に作業の正確性と効率化が図れると思います。
生成AIの大きな利点は、生成AIの基盤である大規模言語モデル(LLM)が従来のコンピュータとは違い、人が話す言葉で生成AIをコントロールできるところにあります。
実務で不定形に並べられた文字郡から必要な情報を引き出すことに、非常に長けているのを実感します。
現在の大規模言語モデルは、かなり高度な質問についても専門性の高い回答を示します。
やはり、回答の精度を左右するのは生成AIへの指示にかかってくるのが現状です。
5 生成AIの答えの精度を上げるチューニング
生成AIには多くのデータから様々なものを学習している一方、全ての情報を100%網羅することは難しいのも事実です。
ですので、この1%にも満たない足らない情報や曖昧な情報をこちらから生成AIに伝え、100%に近い答えを出す状況にする手法が現在主流になっています。
その手法がチューニングと呼ばれるもので、各生成AIの有償バージョンでこのチューニングをすることができます。
具体的には、プレフィックスチューニングやサフィックスチューニングなど様々なものが出てきています。
次回は、事例を用いながら各チューニングについて説明していきます。
《参考文献》
『プログラミング知識ゼロでもわかる プロンプトエンジニアリング入門』掌田津耶乃 著
『Google VertextAl によるアプリケーション開発』掌田津耶乃 著

神奈川県川崎市で税理士・社会保険労務士をお探しなら
経営者のパートナーとして中小企業の皆さまをサポートします

“第70回 業務に生成AIを活用する方法②” に対して1件のコメントがあります。
コメントは受け付けていません。